Osa 2: Rakenna ensimmäinen AI-agenttisi – Käytännön opas LangChainilla
Useimmat AI-agenttioppaat sivuuttavat kehityksen sotkuiset yksityiskohdat. Näin rakensin toimivan agentin LangChainilla, tRPC:llä ja PostgreSQL:llä – mukaan lukien kaikki matkan varrella tekemäni virheet.
Title: Rakensin oikean AI-agentin tyhjästä – Tässä on totuus hypen takana Excerpt: AI-agenttien ympärillä pyörivä hype on todellista, mutta useimmat tutoriaalit näyttävät vain silotellun totuuden. Rakensin oikean, tuotantokelpoisen agentin kahdessa päivässä. Tässä on tarkka kuvaus siitä, miten se tehtiin – mukaan lukien ne asiat, jotka menivät aluksi pieleen.
AI-agenttien ympärillä pyörivä hype on todellista. Kaikki puhuvat autonomisista järjestelmistä, jotka osaavat ajatella, suunnitella ja suorittaa tehtäviä. Mutta tässä on se asia, josta kukaan ei kerro: useimmat tutoriaalit näyttävät vain "onnellisen polun" (happy path) ja sivuuttavat ne kohdat, joissa asiat hajoavat.
Viime viikolla käytin kaksi päivää AI-agentin rakentamiseen tyhjästä. Kyseessä ei ole mikään lelu-esimerkki, vaan oikea sovellus, joka hallinnoi blogialustaa, luo käyttäjiä, kirjoittaa postauksia ja toimii oikeasti. Aion näyttää tarkalleen, miten tein sen – mukaan lukien ne osat, jotka eivät toimineet ensimmäisellä kerralla.
Koko koodi: github.com/giftedunicorn/my-ai-agent
Mitä olemme oikeasti rakentamassa
Unohda abstraktit esimerkit. Rakennamme agentin, joka:
- Luo ja hallinnoi käyttäjiä PostgreSQL-tietokannassa
- Generoi blogipostauksia pyynnöstä
- Vastaa keskustelevasti käyttäen samalla työkaluja
- Ylläpitää keskusteluhistoriaa
- On oikeasti deployattu (eikä vain localhost-demo)
Teknologiat (Stack): Next.js, tRPC, Drizzle ORM, LangChain ja Googlen Gemini. Ei siksi, että se on trendikästä, vaan koska se on tyyppiturvallinen, nopea ja toimii oikeasti tuotannossa.
Arkkitehtuuri (Yksinkertaisempi kuin luulet)
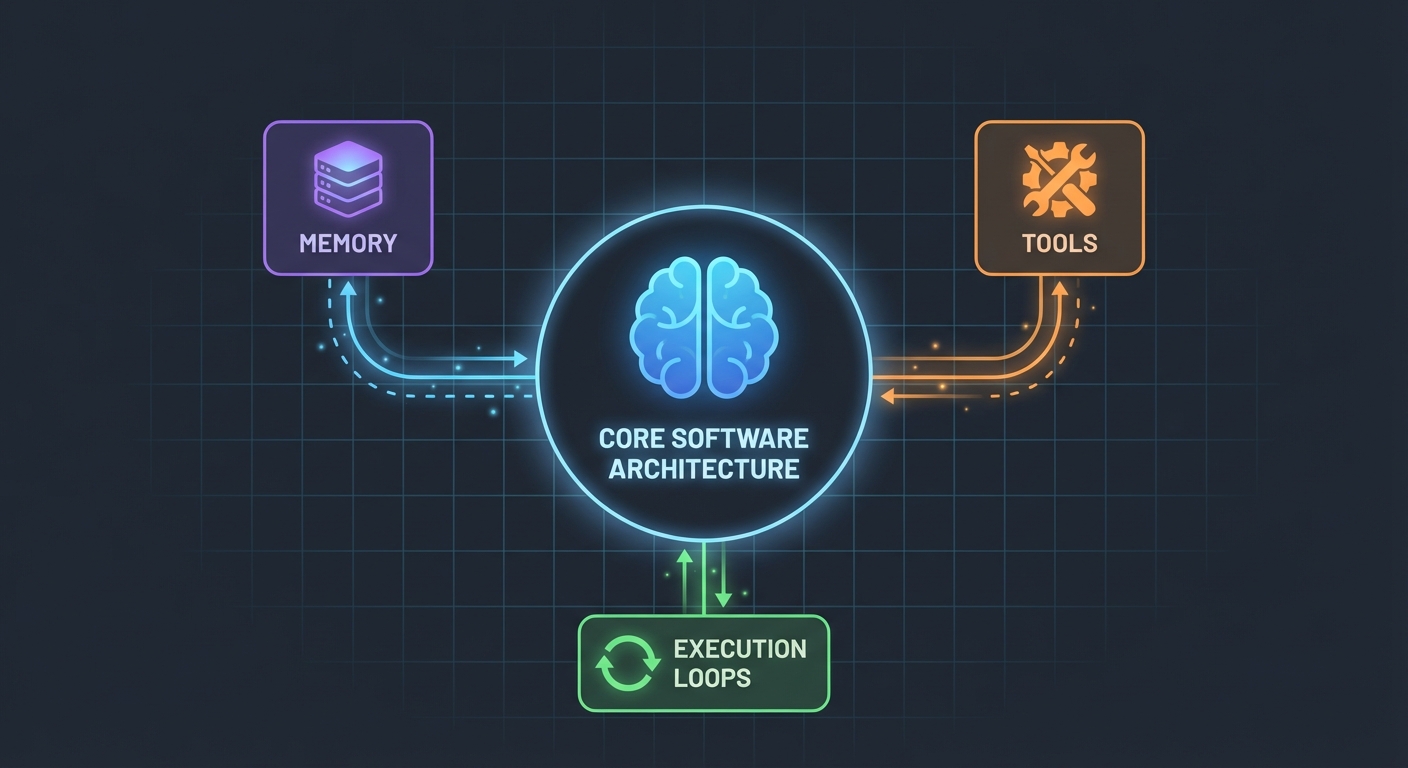
Tämä yllätti minut: AI-agentit eivät ole niin monimutkaisia. Pohjimmiltaan ne ovat vain:
- LLM, joka osaa kutsua funktioita
- Joukko työkaluja, joita LLM voi käyttää
- Silmukka (loop), joka suorittaa nämä työkalut
- Muisti kontekstin ylläpitämiseen
Siinä se. Monimutkaisuus syntyy siitä, että nämä palaset saadaan toimimaan luotettavasti yhdessä.
Tietokantaskeema
Ensin perusta. Tarvitsemme taulut käyttäjille, postauksille ja viesteille:
export const User = pgTable("user", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
name: t.varchar({ length: 255 }).notNull(),
email: t.varchar({ length: 255 }).notNull().unique(),
bio: t.text(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
export const Post = pgTable("post", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
userId: t
.integer()
.notNull()
.references(() => User.id, { onDelete: "cascade" }),
title: t.varchar({ length: 500 }).notNull(),
content: t.text().notNull(),
published: t.boolean().default(false).notNull(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
Ei mitään ihmeellistä. Vain puhdasta relaatiodataa PostgreSQL:llä. Message-taulu tallentaa keskusteluhistorian – tämä on kriittistä kontekstin säilyttämiseksi pyyntöjen välillä.
Työkalujen rakentaminen (Missä taika tapahtuu)
Tässä kohtaa useimmat tutoriaalit jäävät epämääräisiksi. "Luo vain joitakin työkaluja", ne sanovat. Anna kun näytän, miltä se oikeasti näyttää.
Työkalut ovat funktioita, joita tekoälysi voi kutsua. LangChainin DynamicStructuredTool -avulla määrittelet:
- Mitä työkalu tekee (kuvaus)
- Mitä syötteitä se tarvitsee (skeema Zodilla)
- Mitä se oikeasti suorittaa (funktio)
Tässä on työkalu käyttäjien luomiseen:
const createUserTool = new DynamicStructuredTool({
name: "create_user",
description:
"Create a new user in the database. Use this when asked to add, create, or register a user.",
schema: z.object({
name: z.string().describe("The user's full name"),
email: z.string().email().describe("The user's email address"),
bio: z.string().optional().describe("Optional biography"),
}),
func: async (input) => {
const { name, email, bio } = input as {
name: string;
email: string;
bio?: string;
};
const user = await caller.user.create({ name, email, bio });
return `Successfully created user: ${user.name} (ID: ${user.id}, Email: ${user.email})`;
},
});
Kuvauksella on enemmän merkitystä kuin uskoisitkaan. LLM käyttää sitä päättääkseen, milloin tätä työkalua kutsutaan. Ole täsmällinen sen suhteen, milloin sitä tulee käyttää.
Paluuarvo? Se on se, minkä LLM näkee. Palautan strukturoitua tekstiä, jossa on kaikki olennaiset tiedot – ID:t, nimet, vahvistukset. Tämä auttaa LLM:ää antamaan parempia vastauksia käyttäjille.
Agentti: Kaiken kokoaminen yhteen
Tässä homma muuttuu mielenkiintoiseksi. Uusi LangChain API (v1.2+) yksinkertaisti kaiken:
const agent = createAgent({
model: new ChatGoogleGenerativeAI({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
model: "gemini-2.0-flash-exp",
temperature: 0.7,
}),
tools: [...createUserTools(caller), ...createPostTools(caller)],
systemPrompt: AGENT_SYSTEM_PROMPT,
});
const result = await agent.invoke({
messages: conversationMessages,
});
Siinä se. Ei ChatPromptTemplatea, ei AgentExecutoria, ei monimutkaisia ketjuja. Vain createAgent ja invoke.
System Prompt (Agenttisi persoonallisuus)
Tässä opetat agenttisi käyttäytymään:
const AGENT_SYSTEM_PROMPT = `You are an AI assistant that helps manage a blog platform.
You have access to tools for:
- User management (create, read, list, count)
- Post management (create, list)
When users ask you to perform actions:
1. Use the appropriate tools to complete the task
2. Be conversational and friendly
3. Provide clear confirmation with specific details
4. When creating mock data, use realistic names and content
Always confirm successful operations with relevant details.`;
Opin tämän kantapään kautta: ole eksplisiittinen. Kerro agentille tarkalleen mitä tehdä, miten vastata ja mitä yksityiskohtia sisällyttää. Epämääräiset kehotteet johtavat epämääräiseen käytökseen.
Keskusteluhistorian käsittely
Useimmat esimerkit sivuuttavat tämän, mutta se on kriittistä hyvän käyttökokemuksen kannalta. Näin minä hoidan sen:
// Get last 10 messages from database
const history = await ctx.db
.select()
.from(Message)
.orderBy(desc(Message.createdAt))
.limit(10);
// Convert to LangChain format
const conversationMessages = [
...history.reverse().map((msg) => ({
role: msg.role === "user" ? "user" : "assistant",
content: msg.content,
})),
{ role: "user", content: input.message },
];
Yksinkertaista, mutta tehokasta. Agentti muistaa nyt viimeiset 10 viestinvaihtoa. Tarpeeksi kontekstia varten, mutta ei niin paljoa, että se menisi sekaisin tai tulisi kalliiksi.
Sotkuiset osat (Mikä oikeasti hajosi)
Kehäriippuvuudet (Circular Dependencies): Ensimmäinen yritykseni epäonnistui, koska agent.ts toi (import) appRouter:in, joka toi agentRouter:in, mikä loi kehäriippuvuuden. Ratkaisu? Luo väliaikainen router inline-tyylisesti vain niillä reitittimillä, joita tarvitset työkaluja varten.
Työkalun vastauksen poiminta: LangChainin vastausformaatti muuttui versiossa 1.2. Tulos on nyt result.messages[result.messages.length - 1].content, eikä result.output. Tämän selvittämiseen meni tunti.
Tyyppiturvallisuus: Työkalun func-parametri tarvitsee eksplisiittisen tyypityksen. Et voi vain destrukturoida – sinun täytyy "castata" input ensin. TypeScript ei auta sinua tässä automaattisesti.
Oman agentin pystyttäminen
Tässä on se, mitä oikeasti tarvitset:
- Asenna riippuvuudet:
pnpm add @langchain/core @langchain/google-genai langchain drizzle-orm
- Ympäristömuuttujat:
POSTGRES_URL="your-database-url" # Kokeile Vercel Postgresia, Supabasea tai lokaalia PostgreSQL:ää
GOOGLE_GENERATIVE_AI_API_KEY="your-gemini-key" # Hae osoitteesta https://aistudio.google.com/app/apikey
- Tietokannan alustus:
pnpm db:push # Luo taulut skeemasta
- Aloita rakentaminen:
- Määrittele tietokantaskeema
- Luo tRPC-proseduurit CRUD-operaatioille
- Rakenna LangChain-työkalut, jotka käärivät nuo proseduurit
- Luo agentti työkaluillasi
- Kytke se frontendiin
Mitä tekisin toisin
Jos aloittaisin alusta huomenna:
Aloita vähemmillä työkaluilla. Rakensin aluksi 7 työkalua. Pysy ensin 3-4 ydintyökalussa. Saa ne toimimaan täydellisesti, ja laajenna vasta sitten.
Testaa työkaluja itsenäisesti. Älä odota, että agentti on valmis testataksesi työkalujasi. Kutsu niitä suoraan testidatalla ensin.
Seuraa työkalujen käyttöä. Lisäsin lokituksen nähdäkseni, mitä työkaluja agentti kutsuu ja miksi. Tämä paljasti, että työkalujeni kuvaukset vaativat hiomista.
Käytä striimausta. Tällä hetkellä käyttäjät odottavat koko vastausta. Striimaus saisi sen tuntumaan nopeammalta, vaikka se kestäisi saman verran aikaa.
Todellisuustarkistus
AI-agenttien rakentaminen ei ole taikuutta, mutta se ei ole myöskään triviaalia. Tulet käyttämään enemmän aikaa:
- Työkalujen suunnitteluun (mitä kunkin työkalun pitäisi tehdä?)
- Prompt engineeringiin (miten saan agentin käyttäytymään oikein?)
- Virheiden käsittelyyn (mitä jos tietokanta on alhaalla? mitä jos LLM hallusinoi?)
- Tyyppiturvallisuuteen (TypeScriptin pitäminen tyytyväisenä dynaamisten LLM-vastausten kanssa)
Kuin itse tekoälyosuuteen.
Kokeile itse
Tämän tutoriaalin koodi on aitoa – rakensin sen samalla kun kirjoitin tätä. Voit:
- Testata sitä: "create 3 mock users"
- Kokeilla: "create 2 blog posts for user 1"
- Kysyä: "how many users do we have?"
Agentti hoitaa kaikki nämä päättämällä mitä työkaluja kutsua, suorittamalla ne ja vastaamalla keskustelevasti.
Mitä seuraavaksi
Tämä on vasta perusta. Tästä eteenpäin voisit:
- Lisätä autentikaation (kuka saa luoda mitä?)
- Toteuttaa striimatut vastaukset
- Lisätä monimutkaisempia työkaluja (haku, analytiikka, integraatiot)
- Rakentaa palautesilmukan (onnistuiko työkalun kutsu?)
- Lisätä rate limitingin (älä anna käyttäjien luoda 10 000 postausta)
Mutta aloita yksinkertaisesti. Saa yksi työkalu toimimaan hyvin ennen kuin lisäät kymmenen keskinkertaista.
Paras osa? Kun ymmärrät tämän kaavan – työkalut + LLM + muisti – voit rakentaa agentteja mihin tahansa. Tietokannan hallintaan, asiakastukeen, sisällöntuotantoon, mihin vain.
Vaikein osuus ei ole koodi. Vaan sellaisten työkalujen suunnittelu, jotka ratkaisevat oikeita ongelmia.
Resurssit:
- Koko lähdekoodi: github.com/giftedunicorn/my-ai-agent
- Rakennettu Create T3 Turbolla
- LangChain Dokumentaatio: js.langchain.com
- Hae Gemini API -avain: aistudio.google.com
Jaa tämä

Kirjoittanut Feng Liu
shenjian8628@gmail.com