The Open-Source LLM Showdown: Which Model Should Solo Founders Actually Use for Agentic Coding in May 2026
DeepSeek cut prices 75%. Cursor Composer 2.5 costs $0.55/task. Here's the actual decision framework for solo founders choosing agentic coding models in May 2026.
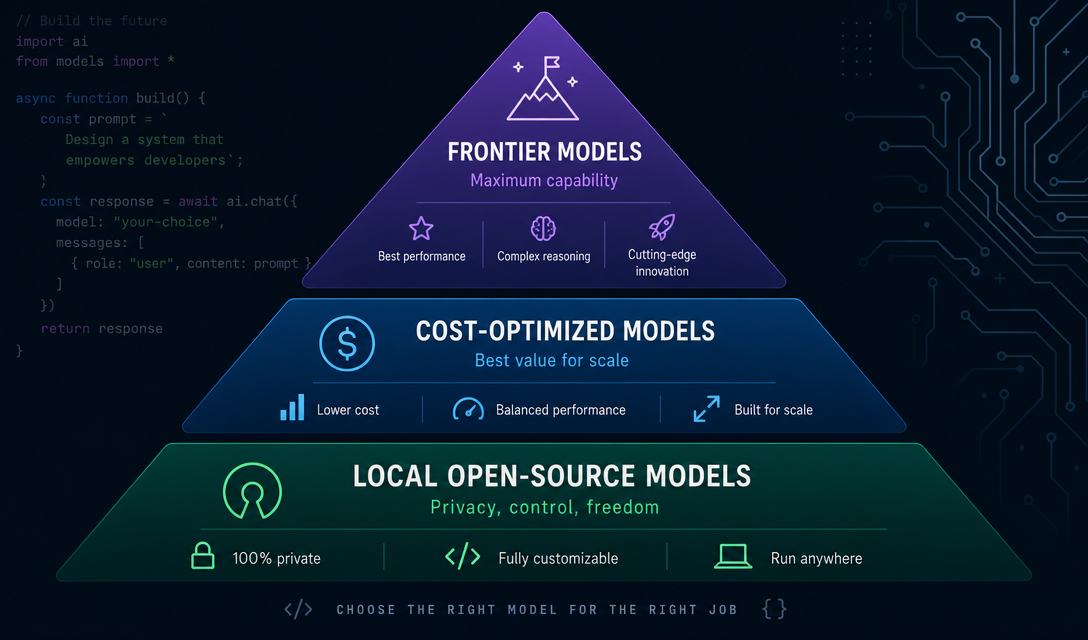
The frontier model pricing race got interesting this week. DeepSeek permanently cut V4-Pro prices by 75%, effective June 1 — input tokens drop to $0.14/M, output to $0.28/M. Cursor Composer 2.5 launched on a fine-tuned Kimi K2.5 checkpoint at $0.50/M input. And the May 2026 Artificial Analysis Index shows the open-source tier is now genuinely competitive with paid frontier models on coding benchmarks.
So if you're a solo founder running agentic workflows — not a research lab, not an enterprise with compliance requirements — which model do you actually reach for?
This is the question I've been working through. Here's where I landed.
The Model Landscape Has Fractured Into Three Tiers
The useful mental model right now isn't "open vs. closed" — it's speed-cost-capability triads. Where you sit on that triangle determines everything.
Tier 1: Frontier closed models — GPT-5.5, Claude Opus 4.7, Qwen 3.7 Max. These are the benchmark leaders, but you pay for it. GPT-5.5 at $5/$30 per million tokens is defensible for high-stakes one-shot tasks (complex refactors, architecture decisions). Qwen 3.7 Max at $2.50/$7.50 is about 50% cheaper than Opus 4.7 and beat it on SWE-Bench Pro and Terminal-Bench 2.0. If you're not locked into Anthropic's ecosystem, that's worth a look.
Tier 2: Cost-optimized agentic models — Cursor Composer 2.5, Gemini 3.5 Flash, DeepSeek V4 Pro. This is where the real value is for builders right now. Cursor Composer 2.5 hits 63.2% on CursorBench v3.1 (beating GPT-5.5 on IDE-specific tasks), runs on Kimi K2.5, and costs ~$0.55 per typical agentic task. Gemini 3.5 Flash comes in at $1.50/$9 per million tokens with 4x the speed of Gemini 3.1 Pro. DeepSeek V4 Pro, post-June-1 pricing, is essentially free to experiment with at $0.14 input.
Tier 3: Fully local open-source — Qwen 3.6-27B, Llama 4 Scout, Mistral Small 4. These run on Ollama or LM Studio, zero API cost, total privacy. Qwen 3.6-27B is the best small dense coder right now — 77.2% SWE-Bench Verified, Apache-2.0 license. The tradeoff is hardware requirements and setup time.
The Actual Decision Framework
Four questions, in order:
1. Is the task in the IDE or the terminal? This matters more than people admit. Cursor Composer 2.5 dominates IDE-specific workflows but trails GPT-5.5 on terminal-heavy tasks (69.3% vs 82.7% Terminal-Bench 2.0). If your agentic loop is heavily terminal-based — CI/CD automation, infrastructure scripting, long-horizon bash chains — you want a different model than if you're doing code completion and refactoring inside an IDE.
2. How sensitive is the data? If you're running an agentic workflow on user data, customer code, or anything that touches PII, local models are not just cheaper — they're the right call from a compliance standpoint. Qwen 3.6-27B on Ollama handles most mid-complexity coding tasks without touching an external API.
3. What's your actual cost per task? People optimize on price-per-token when they should optimize on price-per-completed-task. A cheaper model that requires 3 retries to get a working result costs more than a pricier model that gets it right once. Cursor Composer 2.5's ~$0.55 per task number is meaningful because it's task-normalized, not token-normalized.
4. Are you locked into a tool's model selection? Claude Code uses Anthropic models. Cursor gives you model choice (including Composer 2.5, GPT-5.5, and Opus 4.7). GitHub Copilot is GPT-native. The tooling choice often constrains the model choice more than any benchmark does.
What I'd Actually Do Right Now
If I were setting up a fresh agentic coding stack today for a bootstrapped product:
- Primary IDE agent: Cursor with Composer 2.5 for everyday coding loops. At $0.55/task, it's financially sustainable for high-volume use.
- Complex architecture or refactors: Qwen 3.7 Max (50% cheaper than Opus 4.7, beating it on most coding benchmarks). Worth running evals on your specific codebase before committing.
- Local fallback / data-sensitive tasks: Qwen 3.6-27B on Ollama. Free, capable, and surprisingly good for the size.
- DeepSeek V4 Pro after June 1: At $0.14 input / $0.28 output, it's cheap enough to use for bulk tasks (test generation, documentation, refactoring runs) where you'd previously have avoided the API cost entirely.
The honest answer is that the right stack changes every 6-8 weeks right now. DeepSeek's 75% price cut isn't just a pricing event — it signals that the open-source and semi-open tier is actively competing on cost with the frontier labs in a way that wasn't true 12 months ago.
The Part Nobody Writes About
Benchmarks lie a little. SWE-Bench Verified measures a specific kind of coding task (patching GitHub issues). Terminal-Bench measures a different one. Neither measures what you actually care about: does this model, in this tool, on my specific codebase, complete the task I need reliably enough to be in the loop?
The only benchmark that matters is the one you run on your own code. Pick two or three candidate models, give them the same real task from your backlog, and measure pass rate + cost. That 30-minute eval will tell you more than any leaderboard.
The model landscape is crowded enough now that the right answer for a TypeScript/React solo founder building an AI SaaS is probably different from the right answer for someone building Rust systems code or a Python ML pipeline. Specificity beats consensus picks every time.
DeepSeek at $0.14/M input is worth testing on June 1 regardless of where you land on everything else. At that price, the cost of being wrong is almost nothing.
Jaa tämä

Kirjoittanut Feng Liu
shenjian8628@gmail.com