Codex vs Claude Code: An AI Agent Architecture Tutorial for Solo Founders Who Need to Pick One
Codex vs Claude Code benchmark breakdown for May 2026 — and a practical AI agent architecture framework for solo founders who need to pick the right tool.
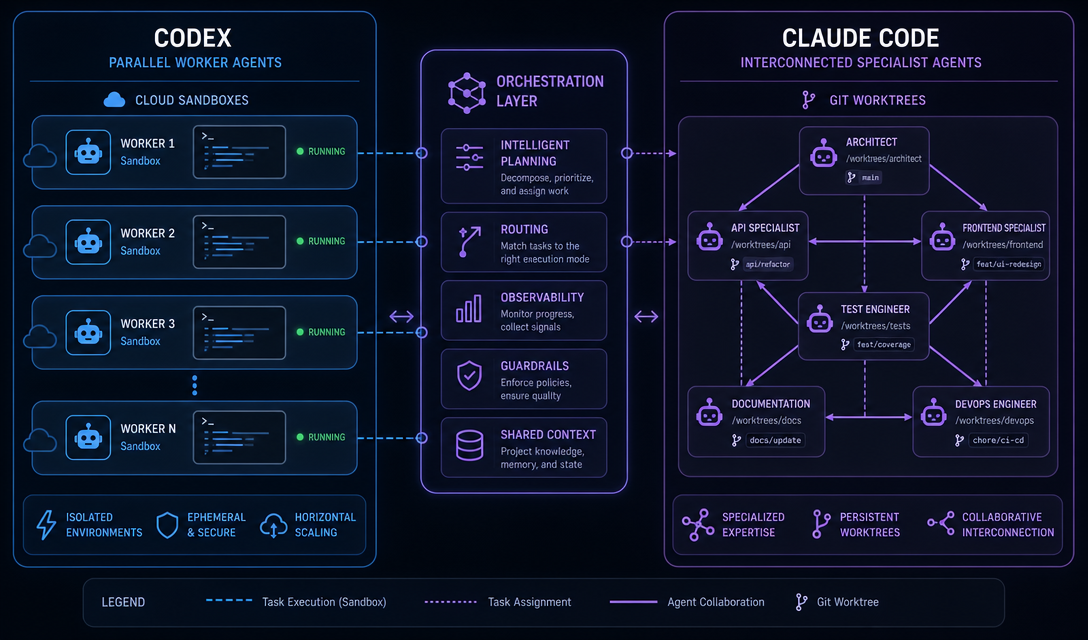
The honest answer to "which AI coding agent should I use" is: it depends on what you're actually trying to build. But that's a useless answer when you're a solo founder with limited token budget, a feature backlog, and no time to A/B test two parallel coding setups.
So here's the breakdown I wish existed when I was making this choice — grounded in the May 2026 benchmark data and the architectural differences that actually matter day-to-day.
The Benchmark Picture (May 2026)
The latest AI agent architecture comparison from MorphLLM gives us concrete numbers for the first time in a while:
- SWE-bench Verified: Codex (GPT-5.5) leads at 88.7% vs Claude Code (Opus 4.7) at 87.6%
- SWE-bench Pro (harder tasks): Claude leads at 64.3% vs Codex at 58.6%
- Terminal-Bench 2.0: Codex dominates at 82.7% vs Claude's 69.4%
- CursorBench: Claude leads (~70% vs Codex)
- Context window: Claude Code 1M tokens vs Codex 200K tokens
The headline: on easy-to-medium software engineering tasks, they're nearly tied. On harder, messier tasks — the kind solo founders actually deal with — Claude pulls ahead. But on long-running autonomous terminal work, Codex is significantly better.
Neither model is universally superior. They're optimized for different jobs.
The Architecture Difference That Changes Everything
Benchmarks tell you what a model can do. Architecture tells you how it works when you're not watching.
Codex uses a manager-worker model: up to 8 parallel agents running in isolated cloud sandboxes, no internet access. It's designed for long-horizon autonomous work — you hand it a task and walk away. The cost-per-productive-hour is lower because it parallelizes effectively.
Claude Code uses what Anthropic calls "Agent Teams" — specialists running on local git worktrees with direct messaging between agents. It's built for complex orchestration, strict plan adherence, and situations where you need agents to coordinate tightly rather than just execute independently.
For the solo founder building an AI agent workflow in Next.js or a multi-step automation: the coordination model matters more than the benchmark score.
If your task is "refactor this module and write tests" — Codex handles that in the background while you work on something else. If your task is "implement auth, update the API contract, and update every downstream service that calls it" — you need Claude's orchestration to keep things consistent.
When to Use Which
Reach for Codex when:
- Long-running tasks that don't need your constant input
- High-volume parallelization (8 agents simultaneously)
- You want to minimize cost per shipped feature
- Terminal-heavy workflows, CI/CD automation
- You have a well-specified task and a clear acceptance criterion
Reach for Claude Code when:
- Complex multi-system changes with coordination requirements
- Tasks that need strict plan adherence — the model is significantly better at not going off-script
- You have a 1M token context window's worth of codebase to hold in memory
- You're doing agentic work that requires orchestrating specialist agents (Claude's Agent Teams, with the new Agent View dashboard as of May 11, 2026)
- You want consistent output across a long session
The Practical Setup I'd Recommend
For most solo founders building AI SaaS, this isn't an either/or. It's a routing question.
The best setup I've seen (and am currently running): Codex for execution, Claude for orchestration.
Specifically:
- Use Claude Code to architect the plan — break the feature into well-scoped tasks with clear interfaces
- Hand the individual tasks to Codex agents for parallel execution
- Return to Claude Code to review, integrate, and handle anything that requires coordinated judgment
This hybrid approach captures Codex's speed and cost efficiency without sacrificing the consistency you get from Claude's planning capability. It maps directly to the manager-worker model Codex uses internally — you're just making the orchestrator explicit.
On Context Windows: 1M vs 200K
This is underrated. A 1M token context window isn't just "more room" — it's a qualitatively different operating mode for large codebases.
If your codebase is under 50K tokens (a small-to-medium SaaS), context limits don't matter much. If you're working on something that's grown to 200K+ tokens of relevant code, Claude Code being able to hold your entire context in a single session is a meaningful advantage. You spend less time resetting context, less time on /compact commands, and fewer dropped threads.
For a solo founder early in the build, Codex's 200K is probably sufficient. As the codebase matures, the 1M limit becomes a real differentiator.
The Cost Reality
Codex's lower cost-per-productive-hour is real — the parallel agent model means you're getting more done per dollar on high-volume task batches. But Claude Code's advantage on SWE-bench Pro (the harder tasks) means you may need fewer retries on complex features, which offsets the per-token cost difference.
For solo founders watching token spend, the practical guidance: use Codex as your default workhorse, escalate to Claude Code for anything that's failed once or involves multi-system coordination.
The Honest Bottom Line
If I had to pick one to start with: Claude Code, because complex orchestration is the bottleneck, not raw execution speed.
But "just use Claude Code" is incomplete advice in 2026. The real unlock for solo founders is treating these as complementary tools in a routing architecture — not rivals you have to choose between.
Build your AI agent architecture around the task type, not the brand loyalty. The benchmarks will keep shifting anyway. Codex just pushed to 88.7% on SWE-bench Verified. Claude will respond. The underlying architecture decisions — how you scope tasks, how you orchestrate specialists, how you manage context — those are durable.
That's where the leverage actually is.
Partager ceci

Écrit par Feng Liu
shenjian8628@gmail.com