2부: LangChain으로 첫 AI 에이전트 만들기: 실전 가이드
대부분의 AI 에이전트 튜토리얼은 개발 과정의 지저분한 현실을 건너뜁니다. LangChain, tRPC, PostgreSQL을 사용하여 실제로 작동하는 에이전트를 구축한 방법과 그 과정에서 겪은 실수들을 가감 없이 공유합니다.
AI 에이전트(AI Agent) 열풍은 진짜입니다. 모두가 스스로 생각하고, 계획하고, 작업을 수행하는 자율 시스템에 대해 이야기하고 있죠. 하지만 아무도 말해주지 않는 진실이 있습니다. 대부분의 튜토리얼은 모든 게 잘 돌아가는 '해피 패스(happy path)'만 보여주고, 정작 문제가 터지는 부분은 건너뛴다는 것입니다.
지난주, 저는 이틀을 꼬박 투자해 바닥부터 AI 에이전트를 만들었습니다. 장난감 같은 예제가 아닙니다. 블로그 플랫폼을 관리하고, 사용자를 생성하고, 글을 작성하고, 실제로 작동하는 진짜 에이전트입니다. 제가 어떻게 만들었는지, 그리고 첫 시도에서 실패했던 부분까지 포함해 정확한 과정을 보여드리겠습니다.
전체 코드: github.com/giftedunicorn/my-ai-agent
실제로 우리가 만들 것
추상적인 예제는 잊어버리세요. 우리는 다음과 같은 기능을 수행하는 에이전트를 만들 겁니다:
- PostgreSQL 데이터베이스에서 사용자 생성 및 관리
- 요청에 따라 블로그 게시물 생성
- 도구(Tools)를 사용하면서 대화형으로 응답
- 대화 기록(History) 유지
- 실제로 배포 가능 (로컬호스트 데모 아님)
기술 스택: Next.js, tRPC, Drizzle ORM, LangChain, 그리고 Google의 Gemini. 유행이라서가 아닙니다. 타입 안전성(type-safe)이 보장되고, 빠르며, 프로덕션 환경에서 실제로 잘 작동하기 때문입니다.
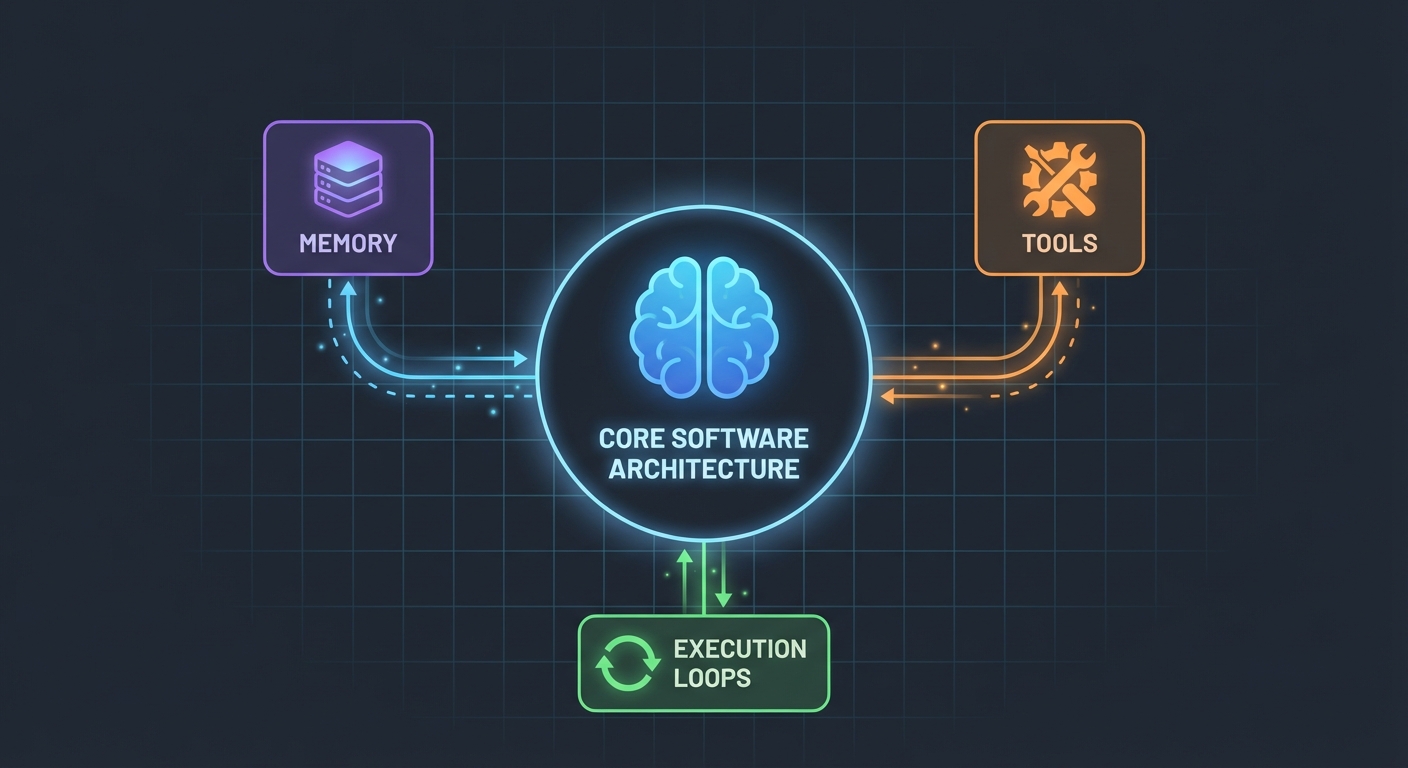
아키텍처 (생각보다 간단합니다)
놀라웠던 점은 이겁니다. AI 에이전트는 생각보다 복잡하지 않습니다. 핵심은 단지 다음과 같습니다:
- 함수를 호출할 수 있는 LLM
- LLM이 사용할 수 있는 도구(Tools) 세트
- 그 도구들을 실행하는 루프(Loop)
- 컨텍스트를 유지하기 위한 메모리(Memory)
그게 전부입니다. 복잡함은 이 조각들이 안정적으로 함께 작동하게 만드는 데서 옵니다.
데이터베이스 스키마
먼저 기초 공사입니다. 사용자(User), 게시물(Post), 메시지(Message)를 위한 테이블이 필요합니다:
export const User = pgTable("user", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
name: t.varchar({ length: 255 }).notNull(),
email: t.varchar({ length: 255 }).notNull().unique(),
bio: t.text(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
export const Post = pgTable("post", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
userId: t
.integer()
.notNull()
.references(() => User.id, { onDelete: "cascade" }),
title: t.varchar({ length: 500 }).notNull(),
content: t.text().notNull(),
published: t.boolean().default(false).notNull(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
화려할 것 없습니다. PostgreSQL을 사용한 깔끔한 관계형 데이터일 뿐입니다. Message 테이블은 대화 기록을 저장하는데, 이는 요청 간의 컨텍스트를 유지하는 데 매우 중요합니다.
도구 만들기 (마법이 일어나는 곳)
대부분의 튜토리얼이 이 부분을 모호하게 넘어갑니다. 그저 "도구를 좀 만드세요"라고 하죠. 실제로 그게 어떤 모습인지 보여드리겠습니다.
도구(Tools)는 AI가 호출할 수 있는 함수입니다. LangChain의 DynamicStructuredTool을 사용하여 다음을 정의합니다:
- 도구가 하는 일 (설명/description)
- 필요한 입력값 (Zod를 사용한 스키마)
- 실제로 실행되는 것 (함수/function)
다음은 사용자를 생성하는 도구입니다:
const createUserTool = new DynamicStructuredTool({
name: "create_user",
description:
"Create a new user in the database. Use this when asked to add, create, or register a user.",
schema: z.object({
name: z.string().describe("The user's full name"),
email: z.string().email().describe("The user's email address"),
bio: z.string().optional().describe("Optional biography"),
}),
func: async (input) => {
const { name, email, bio } = input as {
name: string;
email: string;
bio?: string;
};
const user = await caller.user.create({ name, email, bio });
return `Successfully created user: ${user.name} (ID: ${user.id}, Email: ${user.email})`;
},
});
설명(description)은 생각보다 훨씬 중요합니다. LLM은 이 설명을 보고 언제 이 도구를 호출할지 결정합니다. 언제 사용해야 하는지 구체적으로 적으세요.
반환값은요? 그게 바로 LLM이 보게 되는 내용입니다. 저는 ID, 이름, 확인 메시지 등 모든 관련 세부 정보를 구조화된 텍스트로 반환합니다. 이렇게 하면 LLM이 사용자에게 더 나은 응답을 제공할 수 있습니다.
에이전트: 모든 것을 하나로 연결하기
여기가 흥미로운 부분입니다. 새로운 LangChain API (v1.2+) 덕분에 모든 게 단순해졌습니다:
const agent = createAgent({
model: new ChatGoogleGenerativeAI({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
model: "gemini-2.0-flash-exp",
temperature: 0.7,
}),
tools: [...createUserTools(caller), ...createPostTools(caller)],
systemPrompt: AGENT_SYSTEM_PROMPT,
});
const result = await agent.invoke({
messages: conversationMessages,
});
이게 전부입니다. ChatPromptTemplate도, AgentExecutor도, 복잡한 체인(chains)도 필요 없습니다. 그저 createAgent와 invoke면 됩니다.
시스템 프롬프트 (에이전트의 페르소나)
여기서 에이전트에게 어떻게 행동해야 할지 가르칩니다:
const AGENT_SYSTEM_PROMPT = `You are an AI assistant that helps manage a blog platform.
You have access to tools for:
- User management (create, read, list, count)
- Post management (create, list)
When users ask you to perform actions:
1. Use the appropriate tools to complete the task
2. Be conversational and friendly
3. Provide clear confirmation with specific details
4. When creating mock data, use realistic names and content
Always confirm successful operations with relevant details.`;
저는 이걸 뼈저리게 느꼈습니다: 명확해야 합니다. 에이전트에게 무엇을 해야 하는지, 어떻게 반응해야 하는지, 어떤 세부 정보를 포함해야 하는지 정확히 말해주세요. 모호한 프롬프트는 모호한 행동을 낳습니다.
대화 기록(History) 처리하기
대부분의 예제는 이 부분을 건너뛰지만, 좋은 사용자 경험을 위해서는 필수적입니다. 저는 이렇게 처리했습니다:
// Get last 10 messages from database
const history = await ctx.db
.select()
.from(Message)
.orderBy(desc(Message.createdAt))
.limit(10);
// Convert to LangChain format
const conversationMessages = [
...history.reverse().map((msg) => ({
role: msg.role === "user" ? "user" : "assistant",
content: msg.content,
})),
{ role: "user", content: input.message },
];
단순하지만 효과적입니다. 이제 에이전트는 최근 10번의 대화를 기억합니다. 문맥을 파악하기엔 충분하고, 혼란스러워지거나 비용이 많이 들 정도는 아니죠.
골치 아픈 부분들 (실제로 깨졌던 것들)
순환 참조 (Circular Dependencies): 제 첫 시도는 실패했습니다. agent.ts가 appRouter를 임포트하고, 그게 다시 agentRouter를 임포트하면서 순환 참조가 발생했거든요. 해결책은? 도구에 필요한 라우터만 포함하는 임시 라우터를 인라인으로 만드는 것이었습니다.
도구 응답 추출: LangChain v1.2에서 응답 형식이 변경되었습니다. 결과값은 이제 result.output이 아니라 result.messages[result.messages.length - 1].content에 들어있습니다. 이걸 알아내는 데 한 시간이 걸렸습니다.
타입 안전성 (Type Safety): 도구의 func 매개변수는 명시적인 타이핑이 필요합니다. 그냥 구조 분해 할당(destructure)을 할 수 없습니다. 먼저 input을 캐스팅해야 합니다. TypeScript는 여기서 여러분을 도와주지 않습니다.
직접 설정해보기
실제로 필요한 것은 다음과 같습니다:
- 의존성 설치:
pnpm add @langchain/core @langchain/google-genai langchain drizzle-orm
- 환경 변수:
POSTGRES_URL="your-database-url" # Vercel Postgres, Supabase, 또는 로컬 PostgreSQL 사용
GOOGLE_GENERATIVE_AI_API_KEY="your-gemini-key" # https://aistudio.google.com/app/apikey 에서 발급
- 데이터베이스 설정:
pnpm db:push # 스키마를 기반으로 테이블 생성
- 구축 시작:
- 데이터베이스 스키마 정의
- CRUD 작업을 위한 tRPC 프로시저 생성
- 해당 프로시저를 래핑하는 LangChain 도구 구축
- 도구를 포함한 에이전트 생성
- 프론트엔드와 연결
다시 한다면 다르게 할 것들
만약 내일 다시 처음부터 시작한다면:
더 적은 도구로 시작할 겁니다. 처음에는 7개의 도구를 만들었습니다. 핵심 도구 3-4개만 먼저 만드세요. 그것들이 완벽하게 작동하면 그때 확장하세요.
도구를 독립적으로 테스트하세요. 에이전트가 완성될 때까지 기다리지 말고 도구를 테스트하세요. 테스트 데이터로 직접 호출해보세요.
도구 사용을 모니터링하세요. 저는 에이전트가 어떤 도구를 왜 호출하는지 보기 위해 로깅을 추가했습니다. 이를 통해 제 도구 설명(description)을 수정해야 한다는 걸 알게 되었죠.
스트리밍을 사용하세요. 지금은 사용자가 전체 응답을 기다려야 합니다. 스트리밍을 적용하면 시간은 똑같이 걸려도 훨씬 빠르게 느껴질 겁니다.
현실 점검 (Reality Check)
AI 에이전트 구축은 마법이 아니지만, 그렇다고 사소한 일도 아닙니다. 여러분은 실제 AI 부분보다 다음 작업에 더 많은 시간을 쓰게 될 겁니다:
- 도구 설계 (각 도구는 무엇을 해야 하는가?)
- 프롬프트 엔지니어링 (어떻게 하면 에이전트가 올바르게 행동할까?)
- 에러 처리 (데이터베이스가 다운되면? LLM이 환각(hallucination)을 일으키면?)
- 타입 안전성 (동적인 LLM 응답에 대해 TypeScript 만족시키기)
직접 해보세요
이 튜토리얼의 코드는 진짜입니다. 이 글을 쓰면서 실제로 만들었으니까요. 여러분은 다음을 할 수 있습니다:
- 테스트: "create 3 mock users" (가짜 사용자 3명 만들어줘)
- 시도: "create 2 blog posts for user 1" (사용자 1을 위해 블로그 글 2개 써줘)
- 질문: "how many users do we have?" (우리 사용자 몇 명이야?)
에이전트는 어떤 도구를 호출할지 결정하고, 실행하고, 대화형으로 응답함으로써 이 모든 것을 처리합니다.
다음 단계
이건 단지 기초일 뿐입니다. 여기서부터 여러분은 다음을 할 수 있습니다:
- 인증 추가 (누가 무엇을 생성할 수 있는가?)
- 스트리밍 응답 구현
- 더 복잡한 도구 추가 (검색, 분석, 통합)
- 피드백 루프 구축 (도구 호출이 성공했는가?)
- 속도 제한(Rate limiting) 추가 (사용자가 10,000개의 글을 생성하지 못하게 하기)
하지만 단순하게 시작하세요. 어설픈 도구 10개보다 잘 작동하는 도구 1개를 먼저 만드세요.
가장 좋은 점은요? 일단 '도구 + LLM + 메모리'라는 이 패턴을 이해하면, 무엇이든 에이전트로 만들 수 있다는 겁니다. 데이터베이스 관리, 고객 지원, 콘텐츠 생성 등 무엇이든요.
어려운 건 코드가 아닙니다. 실제 문제를 해결하는 도구를 설계하는 것이죠.
참고 자료:
- 전체 소스 코드: github.com/giftedunicorn/my-ai-agent
- Create T3 Turbo로 제작됨
- LangChain 문서: js.langchain.com
- Gemini API 키 발급: aistudio.google.com
공유하기

작성자 Feng Liu
shenjian8628@gmail.com