Del 2: Bygg din første AI-agent: En praktisk guide med LangChain
De fleste tutorials for AI-agenter hopper over de rotete detaljene. Her er hvordan jeg bygde en fungerende agent med LangChain, tRPC og PostgreSQL – inkludert feilene jeg gjorde underveis.
AI-agent-hypen er ekte. Alle snakker om autonome systemer som kan tenke, planlegge og utføre oppgaver. Men her er det ingen forteller deg: de fleste tutorials viser deg glansbildet og hopper over delene der ting går i stykker.
I forrige uke brukte jeg to dager på å bygge en AI-agent helt fra bunnen av. Ikke et leketøy – et ekte system som administrerer en bloggplattform, oppretter brukere, skriver innlegg og faktisk fungerer. Jeg skal vise deg nøyaktig hvordan jeg gjorde det, inkludert delene som ikke fungerte første gangen.
Full kode: github.com/giftedunicorn/my-ai-agent
Hva vi faktisk bygger
Glem de abstrakte eksemplene. Vi bygger en agent som:
- Oppretter og administrerer brukere i en PostgreSQL-database
- Genererer blogginnlegg på forespørsel
- Svarer konversasjonelt mens den bruker verktøy
- Bevarer historikk i samtalen
- Faktisk deployes (ikke bare localhost-demoer)
Tech-stacken: Next.js, tRPC, Drizzle ORM, LangChain, og Google's Gemini. Ikke fordi det er trendy – men fordi det er typesikkert, raskt og faktisk fungerer i produksjon.
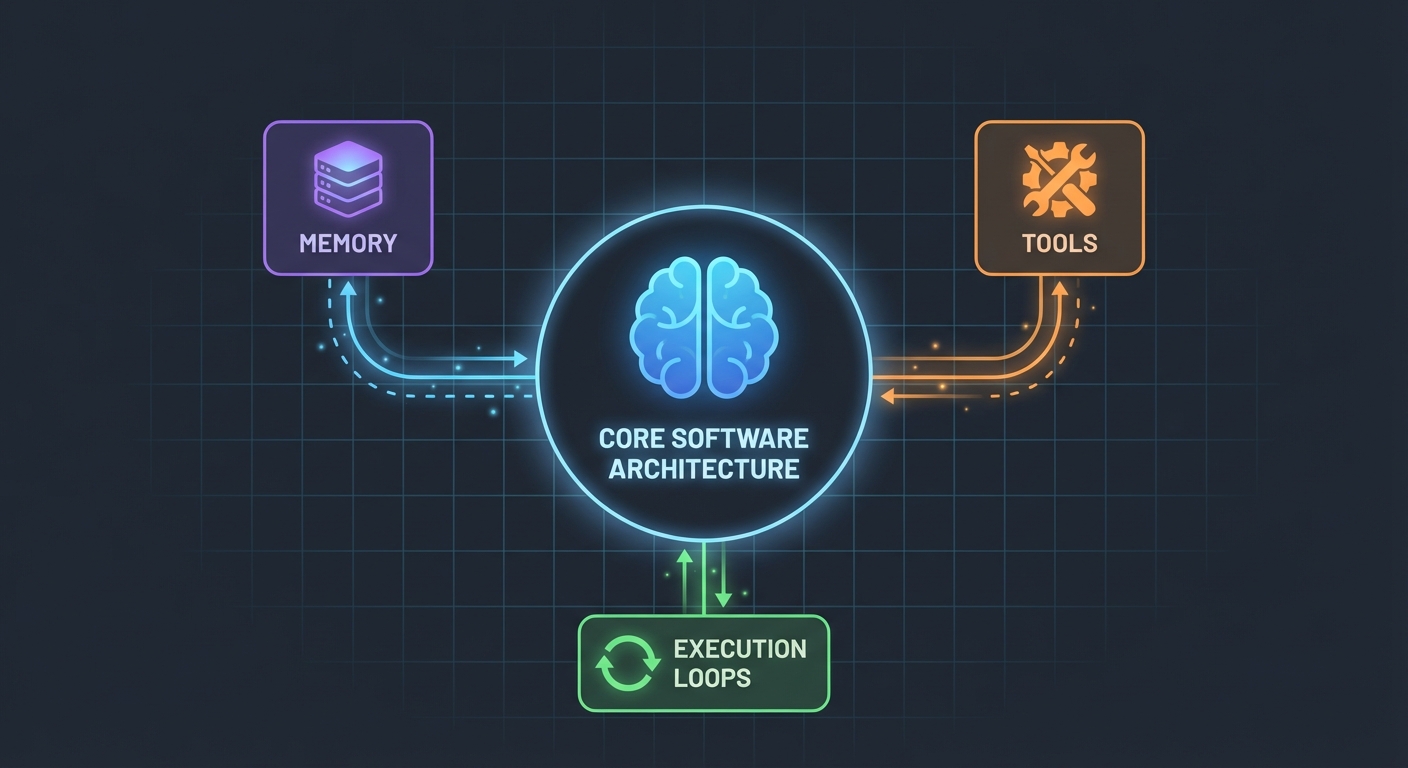
Arkitekturen (Enklere enn du tror)
Her er det som overrasket meg: AI-agenter er ikke så kompliserte. I kjernen er de bare:
- En LLM som kan kalle funksjoner
- Et sett med verktøy LLM-en kan bruke
- En loop som utfører disse verktøyene
- Minne for å bevare kontekst
Det er alt. Kompleksiteten kommer av å få disse bitene til å fungere pålitelig sammen.
Databaseskjemaet
Først, fundamentet. Vi trenger tabeller for brukere, innlegg og meldinger:
export const User = pgTable("user", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
name: t.varchar({ length: 255 }).notNull(),
email: t.varchar({ length: 255 }).notNull().unique(),
bio: t.text(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
export const Post = pgTable("post", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
userId: t
.integer()
.notNull()
.references(() => User.id, { onDelete: "cascade" }),
title: t.varchar({ length: 500 }).notNull(),
content: t.text().notNull(),
published: t.boolean().default(false).notNull(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
Ingenting fancy. Bare ren, relasjonell data med PostgreSQL. Message-tabellen lagrer samtalehistorikken – avgjørende for å bevare kontekst mellom forespørsler.
Bygge verktøyene (Der magien skjer)
Det er her de fleste tutorials blir vage. "Bare lag noen verktøy," sier de. La meg vise deg hvordan det faktisk ser ut.
Verktøy er funksjoner AI-en din kan kalle på. Med LangChains DynamicStructuredTool, definerer du:
- Hva verktøyet gjør (beskrivelse)
- Hvilke inputs det trenger (skjema med Zod)
- Hva det faktisk utfører (funksjon)
Her er verktøyet for å opprette brukere:
const createUserTool = new DynamicStructuredTool({
name: "create_user",
description:
"Create a new user in the database. Use this when asked to add, create, or register a user.",
schema: z.object({
name: z.string().describe("The user's full name"),
email: z.string().email().describe("The user's email address"),
bio: z.string().optional().describe("Optional biography"),
}),
func: async (input) => {
const { name, email, bio } = input as {
name: string;
email: string;
bio?: string;
};
const user = await caller.user.create({ name, email, bio });
return `Successfully created user: ${user.name} (ID: ${user.id}, Email: ${user.email})`;
},
});
Beskrivelsen betyr mer enn du tror. LLM-en bruker den til å bestemme når den skal kalle dette verktøyet. Vær spesifikk om når det skal brukes.
Returverdien? Det er det LLM-en ser. Jeg returnerer strukturert tekst med alle relevante detaljer – ID-er, navn, bekreftelse. Dette hjelper LLM-en med å gi bedre svar tilbake til brukerne.
Agenten: Slik setter vi det sammen
Her blir det interessant. Det nye LangChain API-et (v1.2+) forenklet alt:
const agent = createAgent({
model: new ChatGoogleGenerativeAI({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
model: "gemini-2.0-flash-exp",
temperature: 0.7,
}),
tools: [...createUserTools(caller), ...createPostTools(caller)],
systemPrompt: AGENT_SYSTEM_PROMPT,
});
const result = await agent.invoke({
messages: conversationMessages,
});
Det er alt. Ingen ChatPromptTemplate, ingen AgentExecutor, ingen komplekse chains. Bare createAgent og invoke.
System-prompten (Agentens personlighet)
Det er her du lærer agenten din hvordan den skal oppføre seg:
const AGENT_SYSTEM_PROMPT = `You are an AI assistant that helps manage a blog platform.
You have access to tools for:
- User management (create, read, list, count)
- Post management (create, list)
When users ask you to perform actions:
1. Use the appropriate tools to complete the task
2. Be conversational and friendly
3. Provide clear confirmation with specific details
4. When creating mock data, use realistic names and content
Always confirm successful operations with relevant details.`;
Dette lærte jeg på den harde måten: vær eksplisitt. Fortell agenten nøyaktig hva den skal gjøre, hvordan den skal svare, og hvilke detaljer den skal inkludere. Vage prompts fører til vag oppførsel.
Håndtering av samtalehistorikk
De fleste eksempler hopper over dette, men det er kritisk for en god brukeropplevelse. Slik håndterer jeg det:
// Get last 10 messages from database
const history = await ctx.db
.select()
.from(Message)
.orderBy(desc(Message.createdAt))
.limit(10);
// Convert to LangChain format
const conversationMessages = [
...history.reverse().map((msg) => ({
role: msg.role === "user" ? "user" : "assistant",
content: msg.content,
})),
{ role: "user", content: input.message },
];
Enkelt, men effektivt. Agenten husker nå de siste 10 utvekslingene. Nok for kontekst, men ikke så mye at den blir forvirret eller dyr i drift.
De rotete delene (Hva som faktisk gikk galt)
Sirkulære avhengigheter: Mitt første forsøk feilet fordi agent.ts importerte appRouter, som igjen importerte agentRouter, noe som skapte en sirkulær avhengighet. Løsningen? Lag en midlertidig router inline med kun de routerne du trenger for verktøyene.
Utpakking av verktøy-respons: LangChains responsformat endret seg i v1.2. Resultatet ligger nå i result.messages[result.messages.length - 1].content, ikke result.output. Dette tok meg en time å finne ut av.
Typesikkerhet: func-parameteren i verktøyet trenger eksplisitt typing. Du kan ikke bare destrukturere – du må caste input først. TypeScript hjelper deg ikke her.
Slik setter du opp din egen
Her er det du faktisk trenger:
- Installer avhengigheter:
pnpm add @langchain/core @langchain/google-genai langchain drizzle-orm
- Miljøvariabler:
POSTGRES_URL="your-database-url" # Prøv Vercel Postgres, Supabase, eller lokal PostgreSQL
GOOGLE_GENERATIVE_AI_API_KEY="your-gemini-key" # Hent fra https://aistudio.google.com/app/apikey
- Database-oppsett:
pnpm db:push # Oppretter tabeller fra skjema
- Begynn å bygge:
- Definer databaseskjemaet ditt
- Lag tRPC-prosedyrer for CRUD-operasjoner
- Bygg LangChain-verktøy som wrapper disse prosedyrene
- Opprett agenten med verktøyene dine
- Koble det opp mot frontend
Hva jeg ville gjort annerledes
Hvis jeg startet på nytt i morgen:
Start med færre verktøy. Jeg bygget 7 verktøy til å begynne med. Hold deg til 3-4 kjernefunksjoner først. Få dem til å fungere perfekt, og utvid deretter.
Test verktøy uavhengig. Ikke vent til agenten er ferdigbygget med å teste verktøyene dine. Kall dem direkte med testdata først.
Overvåk verktøybruk. Jeg la til logging for å se hvilke verktøy agenten kaller og hvorfor. Dette avslørte at verktøybeskrivelsene mine trengte arbeid.
Bruk streaming. Akkurat nå venter brukerne på hele svaret. Streaming ville fått det til å føles raskere, selv om det tar like lang tid.
En realitetssjekk
Å bygge AI-agenter er ikke magi, men det er heller ikke trivielt. Du kommer til å bruke mer tid på:
- Verktøydesign (hva skal hvert verktøy gjøre?)
- Prompt engineering (hvordan får jeg agenten til å oppføre seg riktig?)
- Feilhåndtering (hva om databasen er nede? hva om LLM-en hallusinerer?)
- Typesikkerhet (gjøre TypeScript fornøyd med dynamiske LLM-responser)
Enn på selve AI-delen.
Prøv det selv
Koden for denne guiden er ekte – jeg bygget den mens jeg skrev dette. Du kan:
- Teste den med: "create 3 mock users"
- Prøve: "create 2 blog posts for user 1"
- Spørre: "how many users do we have?"
Agenten håndterer alle disse ved å bestemme hvilke verktøy den skal kalle, utføre dem, og svare konversasjonelt.
Veien videre
Dette er bare fundamentet. Herfra kan du:
- Legge til autentisering (hvem kan opprette hva?)
- Implementere streaming av svar
- Legge til mer komplekse verktøy (søk, analyse, integrasjoner)
- Bygge en feedback-loop (var verktøykallingen vellykket?)
- Legge til rate limiting (ikke la brukere opprette 10 000 innlegg)
Men start enkelt. Få ett verktøy til å fungere bra før du legger til ti halv gode.
Det beste? Når du forstår dette mønsteret – verktøy + LLM + minne – kan du bygge agenter for hva som helst. Databaseadministrasjon, kundesupport, innholdsgenerering, hva som helst.
Den vanskelige delen er ikke koden. Det er å designe verktøy som faktisk løser virkelige problemer.
Ressurser:
- Full kildekode: github.com/giftedunicorn/my-ai-agent
- Bygget med Create T3 Turbo
- LangChain Docs: js.langchain.com
- Hent Gemini API-nøkkel: aistudio.google.com
Del dette

Skrevet av Feng Liu
shenjian8628@gmail.com