Część 2: Budowa pierwszego Agenta AI – Praktyczny przewodnik z LangChain
Większość tutoriali o agentach AI pomija niewygodne szczegóły. Zobacz, jak zbudowałem działającego agenta na stacku LangChain, tRPC i PostgreSQL – szczerze opisując przy tym błędy, które popełniłem po drodze.
Hype na agentów AI jest prawdziwy. Ale nikt nie mówi ci o tym, co dzieje się, gdy kod przestaje działać.
Hype na agentów AI jest prawdziwy. Wszyscy mówią o autonomicznych systemach, które potrafią myśleć, planować i wykonywać zadania. Ale jest jedna rzecz, o której nikt ci nie mówi: większość tutoriali pokazuje tylko "idealny scenariusz" (happy path) i pomija momenty, w których wszystko się sypie.
W zeszłym tygodniu spędziłem dwa dni budując agenta AI od zera. Nie zabawkowy przykład – ale prawdziwy system, który zarządza platformą blogową, tworzy użytkowników, pisze posty i faktycznie działa. Pokażę wam dokładnie, jak to zrobiłem, włącznie z częściami, które nie zadziałały za pierwszym razem.
Pełny kod: github.com/giftedunicorn/my-ai-agent
Co tak naprawdę budujemy
Zapomnijcie o abstrakcyjnych przykładach. Budujemy agenta, który:
- Tworzy i zarządza użytkownikami w bazie PostgreSQL
- Generuje posty na bloga na żądanie
- Odpowiada w sposób konwersacyjny, używając narzędzi
- Zachowuje historię rozmowy
- Faktycznie się wdraża (to nie tylko demo na localhost)
Stack technologiczny: Next.js, tRPC, Drizzle ORM, LangChain oraz Google Gemini. Nie dlatego, że to modne – ale dlatego, że jest type-safe (bezpieczne typowo), szybkie i faktycznie działa na produkcji.
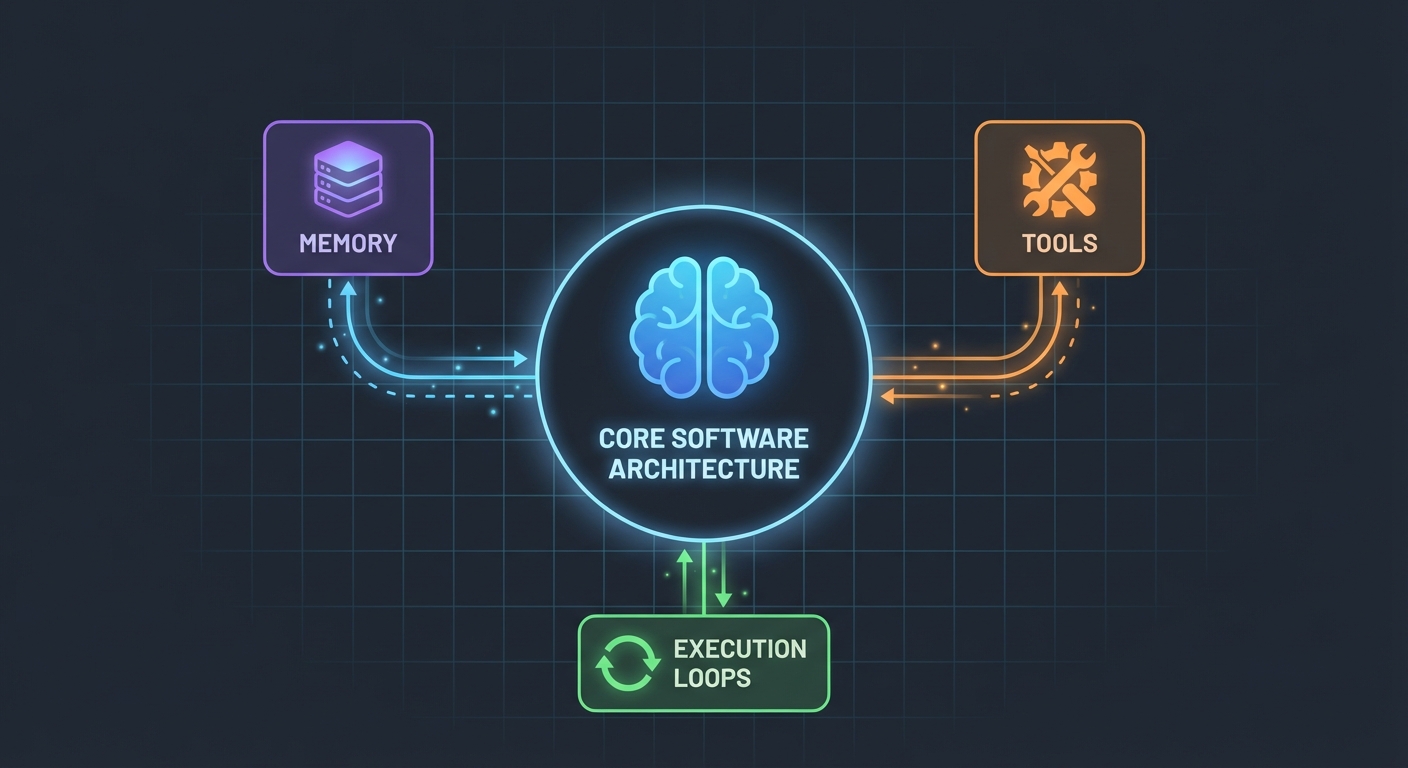
Architektura (Prostsza niż myślisz)
Oto co mnie zaskoczyło: agenci AI wcale nie są tak skomplikowani. W swoim rdzeniu to po prostu:
- LLM, który potrafi wywoływać funkcje
- Zestaw narzędzi, których LLM może używać
- Pętla, która wykonuje te narzędzia
- Pamięć do utrzymania kontekstu
To wszystko. Złożoność bierze się z tego, by sprawić, aby te elementy współpracowały ze sobą niezawodnie.
Schemat Bazy Danych
Najpierw fundamenty. Potrzebujemy tabel dla użytkowników, postów i wiadomości:
export const User = pgTable("user", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
name: t.varchar({ length: 255 }).notNull(),
email: t.varchar({ length: 255 }).notNull().unique(),
bio: t.text(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
export const Post = pgTable("post", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
userId: t
.integer()
.notNull()
.references(() => User.id, { onDelete: "cascade" }),
title: t.varchar({ length: 500 }).notNull(),
content: t.text().notNull(),
published: t.boolean().default(false).notNull(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
Nic wymyślnego. Po prostu czyste, relacyjne dane z PostgreSQL. Tabela Message przechowuje historię rozmowy – co jest kluczowe dla utrzymania kontekstu między zapytaniami.
Budowanie Narzędzi (Gdzie dzieje się magia)
To tutaj większość tutoriali staje się niejasna. "Po prostu stwórz jakieś narzędzia" – mówią. Pozwólcie, że pokażę wam, jak to wygląda w praktyce.
Narzędzia to funkcje, które twoje AI może wywołać. Używając DynamicStructuredTool z LangChain, definiujesz:
- Co narzędzie robi (opis)
- Jakich danych wejściowych potrzebuje (schemat z Zod)
- Co faktycznie wykonuje (funkcja)
Oto narzędzie do tworzenia użytkowników:
const createUserTool = new DynamicStructuredTool({
name: "create_user",
description:
"Create a new user in the database. Use this when asked to add, create, or register a user.",
schema: z.object({
name: z.string().describe("The user's full name"),
email: z.string().email().describe("The user's email address"),
bio: z.string().optional().describe("Optional biography"),
}),
func: async (input) => {
const { name, email, bio } = input as {
name: string;
email: string;
bio?: string;
};
const user = await caller.user.create({ name, email, bio });
return `Successfully created user: ${user.name} (ID: ${user.id}, Email: ${user.email})`;
},
});
Opis (description) ma większe znaczenie, niż myślisz. LLM używa go, by zdecydować, kiedy wywołać to narzędzie. Bądź konkretny w kwestii tego, kiedy go używać.
Wartość zwracana? To właśnie widzi LLM. Zwracam ustrukturyzowany tekst ze wszystkimi istotnymi szczegółami – ID, nazwy, potwierdzenie. To pomaga LLM-owi udzielać użytkownikom lepszych odpowiedzi.
Agent: Składamy to w całość
Tutaj robi się ciekawie. Nowe API LangChain (v1.2+) wszystko uprościło:
const agent = createAgent({
model: new ChatGoogleGenerativeAI({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
model: "gemini-2.0-flash-exp",
temperature: 0.7,
}),
tools: [...createUserTools(caller), ...createPostTools(caller)],
systemPrompt: AGENT_SYSTEM_PROMPT,
});
const result = await agent.invoke({
messages: conversationMessages,
});
To wszystko. Żadnego ChatPromptTemplate, żadnego AgentExecutor, żadnych skomplikowanych łańcuchów (chains). Po prostu createAgent i invoke.
System Prompt (Osobowość Twojego Agenta)
To tutaj uczysz swojego agenta, jak ma się zachowywać:
const AGENT_SYSTEM_PROMPT = `You are an AI assistant that helps manage a blog platform.
You have access to tools for:
- User management (create, read, list, count)
- Post management (create, list)
When users ask you to perform actions:
1. Use the appropriate tools to complete the task
2. Be conversational and friendly
3. Provide clear confirmation with specific details
4. When creating mock data, use realistic names and content
Always confirm successful operations with relevant details.`;
Nauczyłem się tego na błędach: bądź precyzyjny. Powiedz agentowi dokładnie co ma robić, jak odpowiadać i jakie szczegóły uwzględniać. Niejasne prompty prowadzą do niejasnego zachowania.
Obsługa Historii Rozmowy
Większość przykładów to pomija, ale jest to krytyczne dla dobrego User Experience. Oto jak ja to obsługuję:
// Get last 10 messages from database
const history = await ctx.db
.select()
.from(Message)
.orderBy(desc(Message.createdAt))
.limit(10);
// Convert to LangChain format
const conversationMessages = [
...history.reverse().map((msg) => ({
role: msg.role === "user" ? "user" : "assistant",
content: msg.content,
})),
{ role: "user", content: input.message },
];
Proste, ale skuteczne. Agent pamięta teraz ostatnie 10 wymian zdań. Wystarczająco dla kontekstu, ale nie na tyle dużo, by się pogubił lub generował wysokie koszty.
Brudna robota (Co faktycznie się zepsuło)
Cykliczne zależności (Circular Dependencies): Moje pierwsze podejście upadło, ponieważ agent.ts importował appRouter, który importował agentRouter, tworząc pętlę zależności. Rozwiązanie? Stworzenie tymczasowego routera inline tylko z tymi routerami, których potrzebujesz dla narzędzi.
Wyciąganie odpowiedzi z narzędzi: Format odpowiedzi LangChain zmienił się w v1.2. Wynik znajduje się teraz w result.messages[result.messages.length - 1].content, a nie w result.output. Dojście do tego zajęło mi godzinę.
Type Safety: Parametr func w narzędziu wymaga jawnego typowania. Nie możesz po prostu użyć destrukturyzacji – musisz najpierw zrzutować input. TypeScript cię tu nie uratuje.
Konfiguracja u siebie
Oto czego faktycznie potrzebujesz:
- Zainstaluj zależności:
pnpm add @langchain/core @langchain/google-genai langchain drizzle-orm
- Zmienne środowiskowe:
POSTGRES_URL="your-database-url" # Wypróbuj Vercel Postgres, Supabase lub lokalny PostgreSQL
GOOGLE_GENERATIVE_AI_API_KEY="your-gemini-key" # Pobierz z https://aistudio.google.com/app/apikey
- Konfiguracja bazy danych:
pnpm db:push # Tworzy tabele ze schematu
- Zacznij budować:
- Zdefiniuj schemat bazy danych
- Stwórz procedury tRPC dla operacji CRUD
- Zbuduj narzędzia LangChain, które opakowują te procedury
- Stwórz agenta ze swoimi narzędziami
- Podłącz go do swojego frontendu
Co zrobiłbym inaczej
Gdybym zaczynał od nowa jutro:
Zacznij od mniejszej liczby narzędzi. Początkowo zbudowałem 7 narzędzi. Zacznij od 3-4 kluczowych. Doprowadź je do perfekcji, a potem rozszerzaj.
Testuj narzędzia niezależnie. Nie czekaj, aż agent będzie gotowy, by przetestować swoje narzędzia. Wywołuj je bezpośrednio z danymi testowymi.
Monitoruj użycie narzędzi. Dodałem logowanie, by widzieć, które narzędzia agent wywołuje i dlaczego. To ujawniło, że opisy moich narzędzi wymagały poprawy.
Użyj streamingu. Obecnie użytkownicy czekają na pełną odpowiedź. Streaming sprawiłby, że odczucie szybkości byłoby lepsze, nawet jeśli czas wykonania byłby taki sam.
Zderzenie z rzeczywistością
Budowanie agentów AI to nie magia, ale też nie trywialna sprawa. Spędzisz więcej czasu na:
- Projektowaniu narzędzi (co każde narzędzie powinno robić?)
- Inżynierii promptów (jak sprawić, by agent zachowywał się poprawnie?)
- Obsłudze błędów (co jeśli baza danych padnie? co jeśli LLM zacznie halucynować?)
- Bezpieczeństwie typów (zadowalaniu TypeScripta przy dynamicznych odpowiedziach LLM)
Niż na samej części AI.
Spróbuj sam
Kod z tego tutoriala jest prawdziwy – zbudowałem go pisząc ten tekst. Możesz:
- Przetestować go komendą: "create 3 mock users"
- Spróbować: "create 2 blog posts for user 1"
- Zapytać: "how many users do we have?"
Agent obsłuży wszystkie te zapytania, decydując, które narzędzia wywołać, wykonując je i odpowiadając w sposób konwersacyjny.
Co dalej
To dopiero fundament. Stąd możesz:
- Dodać autentykację (kto może co stworzyć?)
- Zaimplementować odpowiedzi strumieniowe (streaming)
- Dodać bardziej złożone narzędzia (wyszukiwanie, analityka, integracje)
- Zbudować pętlę zwrotną (czy wywołanie narzędzia się powiodło?)
- Dodać rate limiting (nie pozwól użytkownikom tworzyć 10 000 postów)
Ale zacznij prosto. Spraw, by jedno narzędzie działało dobrze, zanim dodasz dziesięć przeciętnych.
Najlepsza część? Gdy zrozumiesz ten wzorzec – narzędzia + LLM + pamięć – możesz budować agentów do wszystkiego. Zarządzanie bazą danych, obsługa klienta, generowanie treści, cokolwiek.
Trudna część to nie kod. To projektowanie narzędzi, które faktycznie rozwiązują realne problemy.
Zasoby:
- Pełny kod źródłowy: github.com/giftedunicorn/my-ai-agent
- Zbudowane na Create T3 Turbo
- Dokumentacja LangChain: js.langchain.com
- Pobierz klucz API Gemini: aistudio.google.com
Udostępnij to

Napisane przez Feng Liu
shenjian8628@gmail.com