Часть 2: Создаем первого AI-агента на LangChain: Практическое руководство
Большинство туториалов по AI-агентам обходят стороной самую «грязь» разработки. Я расскажу, как построил рабочего агента на LangChain, tRPC и PostgreSQL — честно, без купюр и со всеми ошибками, которые совершил в процессе.
Хайп вокруг AI-агентов вполне реален. Все говорят об автономных системах, которые могут думать, планировать и выполнять задачи. Но вот о чем молчат: большинство туториалов показывают "идеальный сценарий" (happy path) и пропускают моменты, где всё ломается.
На прошлой неделе я потратил два дня на создание AI-агента с нуля. Не игрушечный пример, а реальный инструмент, который управляет блог-платформой, создает пользователей, пишет посты и действительно работает. Я покажу вам, как именно я это сделал, включая те части, которые не заработали с первого раза.
Полный код: github.com/giftedunicorn/my-ai-agent
Что мы на самом деле строим
Забудьте об абстрактных примерах. Мы строим агента, который:
- Создает и управляет пользователями в базе данных PostgreSQL
- Генерирует посты для блога по запросу
- Поддерживает диалог, используя инструменты
- Сохраняет историю переписки
- Реально деплоится (а не просто демо на localhost)
Стек: Next.js, tRPC, Drizzle ORM, LangChain и Google Gemini. Не потому что это модно, а потому что это типобезопасно, быстро и реально работает в продакшене.
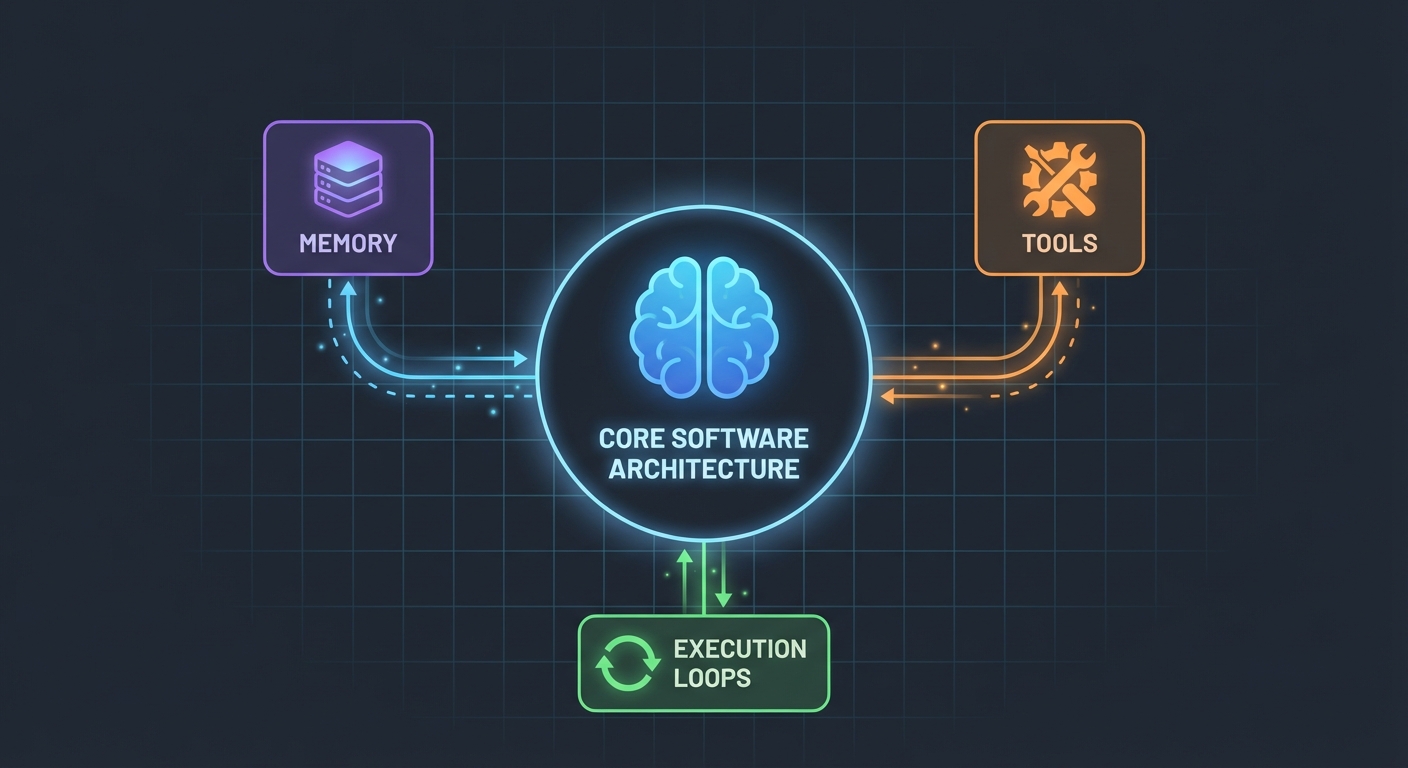
Архитектура (Проще, чем вы думаете)
Вот что меня удивило: AI-агенты не так уж сложны. В своей основе это просто:
- LLM, которая может вызывать функции
- Набор инструментов, которые LLM может использовать
- Цикл, который выполняет эти инструменты
- Память для сохранения контекста
Вот и всё. Сложность заключается в том, чтобы заставить эти части надежно работать вместе.
Схема базы данных
Сначала фундамент. Нам нужны таблицы для пользователей, постов и сообщений:
export const User = pgTable("user", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
name: t.varchar({ length: 255 }).notNull(),
email: t.varchar({ length: 255 }).notNull().unique(),
bio: t.text(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
export const Post = pgTable("post", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
userId: t
.integer()
.notNull()
.references(() => User.id, { onDelete: "cascade" }),
title: t.varchar({ length: 500 }).notNull(),
content: t.text().notNull(),
published: t.boolean().default(false).notNull(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
Ничего необычного. Просто чистые реляционные данные с PostgreSQL. Таблица Message хранит историю переписки — это критически важно для сохранения контекста между запросами.
Создание инструментов (Где происходит магия)
В большинстве туториалов этот момент описан туманно. "Просто создайте несколько инструментов", — говорят они. Позвольте показать, как это выглядит на самом деле.
Инструменты — это функции, которые может вызывать ваш ИИ. С помощью DynamicStructuredTool от LangChain вы определяете:
- Что делает инструмент (описание)
- Какие входные данные ему нужны (схема с Zod)
- Что он фактически выполняет (функция)
Вот инструмент для создания пользователей:
const createUserTool = new DynamicStructuredTool({
name: "create_user",
description:
"Create a new user in the database. Use this when asked to add, create, or register a user.",
schema: z.object({
name: z.string().describe("The user's full name"),
email: z.string().email().describe("The user's email address"),
bio: z.string().optional().describe("Optional biography"),
}),
func: async (input) => {
const { name, email, bio } = input as {
name: string;
email: string;
bio?: string;
};
const user = await caller.user.create({ name, email, bio });
return `Successfully created user: ${user.name} (ID: ${user.id}, Email: ${user.email})`;
},
});
Описание (description) важнее, чем вы думаете. LLM использует его, чтобы решить, когда вызывать этот инструмент. Будьте конкретны в том, когда его использовать.
Возвращаемое значение? Это то, что видит LLM. Я возвращаю структурированный текст со всеми важными деталями — ID, именами, подтверждением. Это помогает LLM давать пользователям более качественные ответы.
Агент: Собираем всё воедино
Здесь становится интересно. Новый API LangChain (v1.2+) всё упростил:
const agent = createAgent({
model: new ChatGoogleGenerativeAI({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
model: "gemini-2.0-flash-exp",
temperature: 0.7,
}),
tools: [...createUserTools(caller), ...createPostTools(caller)],
systemPrompt: AGENT_SYSTEM_PROMPT,
});
const result = await agent.invoke({
messages: conversationMessages,
});
Вот и всё. Никаких ChatPromptTemplate, никаких AgentExecutor, никаких сложных цепочек (chains). Просто createAgent и invoke.
Системный промпт (Личность вашего агента)
Здесь вы учите своего агента, как себя вести:
const AGENT_SYSTEM_PROMPT = `You are an AI assistant that helps manage a blog platform.
You have access to tools for:
- User management (create, read, list, count)
- Post management (create, list)
When users ask you to perform actions:
1. Use the appropriate tools to complete the task
2. Be conversational and friendly
3. Provide clear confirmation with specific details
4. When creating mock data, use realistic names and content
Always confirm successful operations with relevant details.`;
Я усвоил это на горьком опыте: будьте конкретны. Скажите агенту точно, что делать, как отвечать и какие детали включать. Размытые промпты ведут к размытому поведению.
Работа с историей переписки
Большинство примеров это пропускают, но это критически важно для хорошего UX. Вот как я это делаю:
// Получаем последние 10 сообщений из базы данных
const history = await ctx.db
.select()
.from(Message)
.orderBy(desc(Message.createdAt))
.limit(10);
// Конвертируем в формат LangChain
const conversationMessages = [
...history.reverse().map((msg) => ({
role: msg.role === "user" ? "user" : "assistant",
content: msg.content,
})),
{ role: "user", content: input.message },
];
Просто, но эффективно. Агент теперь помнит последние 10 обменов репликами. Достаточно для контекста, но не настолько много, чтобы он запутался или это стало слишком дорого.
Сложные моменты (Что реально ломалось)
Циклические зависимости: Моя первая попытка провалилась, потому что agent.ts импортировал appRouter, который импортировал agentRouter, создавая замкнутый круг. Решение? Создать временный роутер (inline) только с теми роутерами, которые нужны для инструментов.
Извлечение ответа инструмента: Формат ответа в LangChain изменился в v1.2. Результат теперь находится в result.messages[result.messages.length - 1].content, а не в result.output. Я потратил час, чтобы разобраться с этим.
Типобезопасность: Параметр func в инструменте требует явной типизации. Вы не можете просто деструктурировать — нужно сначала привести тип input. TypeScript здесь вам сам не поможет.
Настройка своего проекта
Вот что вам действительно нужно:
- Установите зависимости:
pnpm add @langchain/core @langchain/google-genai langchain drizzle-orm
- Переменные окружения:
POSTGRES_URL="your-database-url" # Попробуйте Vercel Postgres, Supabase или локальный PostgreSQL
GOOGLE_GENERATIVE_AI_API_KEY="your-gemini-key" # Получить здесь: https://aistudio.google.com/app/apikey
- Настройка базы данных:
pnpm db:push # Создает таблицы из схемы
- Начинайте строить:
- Определите схему базы данных
- Создайте процедуры tRPC для CRUD-операций
- Создайте инструменты LangChain, которые оборачивают эти процедуры
- Создайте агента с вашими инструментами
- Подключите его к фронтенду
Что бы я сделал иначе
Если бы я начинал заново завтра:
Начал бы с меньшего количества инструментов. Изначально я создал 7 инструментов. Начните с 3-4 основных. Отладьте их до идеала, затем расширяйте.
Тестировал бы инструменты независимо. Не ждите, пока агент будет готов, чтобы протестировать инструменты. Сначала вызывайте их напрямую с тестовыми данными.
Мониторил бы использование инструментов. Я добавил логирование, чтобы видеть, какие инструменты вызывает агент и почему. Это показало, что описания моих инструментов требовали доработки.
Использовал бы стриминг. Сейчас пользователи ждут полного ответа. Стриминг создал бы ощущение скорости, даже если время выполнения осталось бы прежним.
Проверка реальностью
Создание AI-агентов — это не магия, но и не тривиальная задача. Вы потратите больше времени на:
- Дизайн инструментов (что должен делать каждый инструмент?)
- Промпт-инжиниринг (как заставить агента вести себя правильно?)
- Обработку ошибок (что если база данных лежит? что если LLM галлюцинирует?)
- Типобезопасность (чтобы TypeScript дружил с динамическими ответами LLM)
Чем на саму AI-часть.
Попробуйте сами
Код для этого туториала настоящий — я писал его параллельно с этой статьей. Вы можете:
- Протестировать: "create 3 mock users" (создай 3 тестовых пользователей)
- Попробовать: "create 2 blog posts for user 1" (создай 2 поста для пользователя 1)
- Спросить: "how many users do we have?" (сколько у нас пользователей?)
Агент справляется со всем этим, решая, какие инструменты вызвать, выполняя их и отвечая в формате диалога.
Что дальше
Это только фундамент. Отсюда вы можете:
- Добавить аутентификацию (кто и что может создавать?)
- Реализовать стриминг ответов
- Добавить более сложные инструменты (поиск, аналитика, интеграции)
- Построить цикл обратной связи (успешно ли отработал инструмент?)
- Добавить ограничение частоты запросов (rate limiting), чтобы пользователи не создавали 10 000 постов
Но начните с простого. Заставьте один инструмент работать хорошо, прежде чем добавлять десять посредственных.
Самое лучшее? Как только вы поймете этот паттерн — инструменты + LLM + память — вы сможете создавать агентов для чего угодно. Управление базами данных, поддержка клиентов, генерация контента, что угодно.
Сложная часть — это не код. Это проектирование инструментов, которые действительно решают реальные проблемы.
Ресурсы:
- Полный исходный код: github.com/giftedunicorn/my-ai-agent
- Сделано на Create T3 Turbo
- Документация LangChain: js.langchain.com
- Получить ключ Gemini API: aistudio.google.com
Поделиться

Автор Feng Liu
shenjian8628@gmail.com